Transformer
# Tag:
- Source/KU_ML2
Transformer
RNN기반의 Attention 메커니즘은 병렬 처리가 불가능했으나, Transformer 모델은 Self-Attention을 통한 병렬 처리로 높은 성능 향상을 보여주었다.
이전의 hidden state가 계산되지 않으면 현재 hidden state가 계산 불가능해 순차적으로 처리하던 RNN과 달리, Positional Encoding을 통해 각각의 sequence의 위치를 알고 있어 전체적으로 한번에 계산 가능하게 되므로 병렬 처리가 가능하다.
Positional Encoding
:when is dimension, is time.
만약 순서를 반영하지 않을 경우, 순서를 바꾸어도 동일한 Attention이 나오게 된다.
Sequence data에서는 순서가 중요한 의미를 지니므로, 이를 방지하기 위해 사용한다.
이를 통해 모든 time, dimension마다 다른 값의 Positional Encoding을 추가해 위치 정보를 알아낼 수 있도록 하낟.
Structure
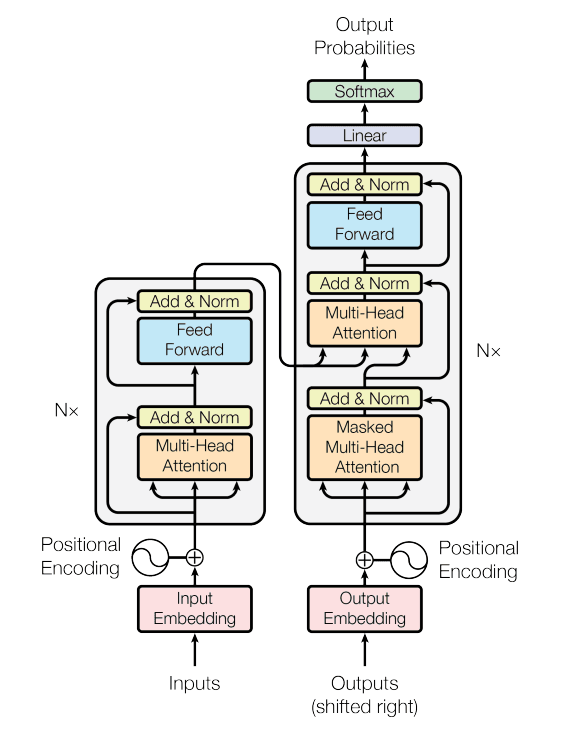
Self-Attention
- Encoder self-attention
- Masked decoder self-attenton: 뒤에 있는 sequence에서 앞에 있는 sequence만을 참조하는 것으로, 출력이 다시 입력으로 들어오는 구조이므로 앞에 만을 참조 가능하다.
Cross-Attention
Encoder-Decoder attention
Multi-Head Attention
Ensemble 개념과 유사하며, Value, Key, Query를 N개의 각각 다른 matrix로 곱하여 서로 다른 N개의 Value, Key, Query를 생성 후 개별적으로 Attention을 수행한다.
마지막에 N개의 state를 concatenate한 후 matrix 연산을 이용해 Linear Transformation을 통해 최종 Context Vector를 계산한다.
Add & norm
Multi-Head Attention을 통해 계산한 Contect Vector와 입력값을 단순히 더한 후 normalization을 수행한다.
Feed Forward
Attention만으로 부족한 Nonlinearity를 더 활용하기 위해 추가한다.